Luat的内存那点事
很多开发者使用Lua进行二次开发时,由于对Lua理解不够深入,导致写出来的代码风格迥异,变量与众不同,思路古灵精怪,运行效率忽高忽低。所以经常能看到很多风骚的写法。
“一夜风流”过后往往留下的都是遍地狼藉。譬如内存不足,语法错误等等。语法错误比较容易排查,但是内存不足怎么办呢?
Air2xx、Air8xx系列模块可供Lua运行的内存是1024k,是非常非常富裕的。造成内存不足的情况是很偶然的,很小概率的。但是,有一些情况下,还是可能因为开发者的小疏忽,造成内存不足。有鉴于此,本文就针对开发者经常可能犯错的地方进行梳理,并提供解决方案以供参考。
一、拼接字符串
有的开发者可能会觉得很奇怪,难道拼接字符串除了效率问题,还会导致内存不足?事实上,的确会这样:我们来看一下代码:
a=””
a=a..”abc”
print(a)
通常,我们可以理解为a就是a,拼接后还是a,所以内存占用就是a的空间;但是,Lua是这样处理字符串的:
--申请内存
a=””
--申请新内存,保存拼接后的字符串,然后a的指针指向新地址
a=a..”abc”
--打印a
print(a)
如此往复,当拼接大量字符串的时候,所占用的内存将远远大于实际使用:
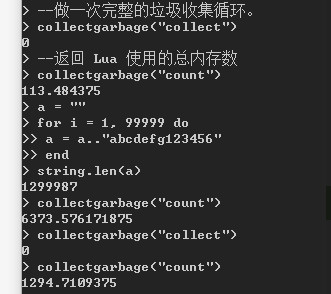
从图中我们可以看出,开始拼接字符串前,lua占用内存是113K,当循环99999次拼接后,内存占用6373k;进行垃圾回收后,占用1294k。
将变量设置为“”,该内存仍然被占用,只有进行垃圾回收,才能彻底释放内存:

如果没有垃圾回收这个步骤,那么6373K的占用,必然消耗掉更多的内存。对于模块只有1024k运存的情况,捉襟见肘了。
譬如需要下载一个150k的文件,ROM剩余空间大于150k,但是因为需要拼接字符串,所以实际占用内存可能超过600k,故此会出现内存不足的情况。所以,如果是http、mqtt、uart这种需要收到字符串并进行拼接的情况,建议应定时回收垃圾,减少内存占用。
二、过长的table
很多开发者可能对table的长度没有概念,所以觉得既然没有什么限制,就往里边随便insert呗。殊不知这样做会拖慢效率,消耗大量内存:
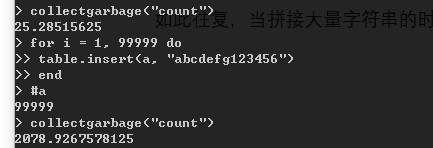
往往并不会插入那么多次字符串,但是其他的对象也是很要命的。所以table的长度要进行控制,而不是无限制的插入。
三、匿名函数
function foo()
return function() print("hello!") end --创建匿名函数,可能会引发内存泄露
end
local helloFunc = foo()
helloFunc()
如果回调过程中大量使用foo(),那么会产生内存泄露。
四、载入过大的文件
由于Luat的运行机制原因,MP3的播放都是先载入内存,再进行播放的。所以MP3文件应尽量小(低码率、单声道),如果体积过大,将导致内存不足。
同样的,如果开发者使用nvm时,config.lua体积过大,也可能出现这个问题。所以开发者保存变量时,应检查后再保存。
开发者在开发过程中,可以根据上述的这几个情况去进行排查,最大限度减少内存泄漏的可能性。同时,开发者应在main.lua中加入如下代码,以保证垃圾自动回收:
collectgarbage("setpause", 90)
更多用法如下:
--collectgarbage("collect"): 做一次完整的垃圾收集循环。通过参数 opt 它提供了一组不同的功能:
--collectgarbage("count"): 以 K 字节数为单位返回 Lua 使用的总内存数。 这个值有小数部分,所以只需要乘上 1024 就能得到 Lua 使用的准确字节数(除非溢出)。
--collectgarbage("restart"): 重启垃圾收集器的自动运行。
--collectgarbage("setpause"): 将 arg 设为收集器的 间歇率。 返回 间歇率 的前一个值。
--collectgarbage("setstepmul"): 返回 步进倍率 的前一个值。
--collectgarbage("step"): 单步运行垃圾收集器。 步长"大小"由 arg 控制。 传入 0 时,收集器步进(不可分割的)一步。 传入非 0 值, 收集器收集相当于 Lua 分配这些多(K 字节)内存的工作。 如果收集器结束一个循环将返回 true 。
--collectgarbage("stop"): 停止垃圾收集器的运行。 在调用重启前,收集器只会因显式的调用运行。
如果开发者一时无法定位问题所在,那么应间隔N秒打印一次当前内存,根据内存波动曲线和代码正在执行的动作,去排查具体原因:
sys.timerStart(function() log.info(“Mem
Free Size:”, 1024- collectgarbage("count")) end, 5000)
- 发表于 2018-09-05 12:56
- 阅读 ( 7998 )
- 分类:默认分类
43 篇文章
